Here’s something most people don’t realize about turning AI chatbot output into affiliate revenue. spaCy’s best general-purpose transformer NER scores only about 0.60 F1 on the PRODUCT label, far below the 0.95-plus it hits on PERSON and GPE (places), so a surprising share of the products your chatbot mentions never get cleanly matched. That accuracy gap is the core reason product extraction is harder than it sounds on paper.
Chatbots mention products the way a knowledgeable friend would, in phrases like “the Anker one” or “grab the PowerCore 10K,” not in tidy catalog strings. You need to catch those mentions, resolve them to a real SKU, and do it inside the latency budget of a live response.
This guide walks through the six decisions that shape a working product extraction pipeline in 2026, from picking NER versus LLM extraction to measuring entity-level accuracy the way affiliate revenue actually cares about.
- spaCy's best transformer model scores 0.605 F1 on the PRODUCT label
- GPT-4-class LLM extraction lands at 85 to 91 percent F1 on e-commerce benchmarks
- LLM extraction is 7 to 30 times slower than local NER
- Prompt-only extraction without constrained decoding has a 5 to 20 percent failure rate
- Dialogue has "low information density and high personal pronoun frequency," degrading entity accuracy
Ask ChatGPT to summarize the full text automatically.
How Should You Choose Between NER, LLM Extraction, or a Hybrid?
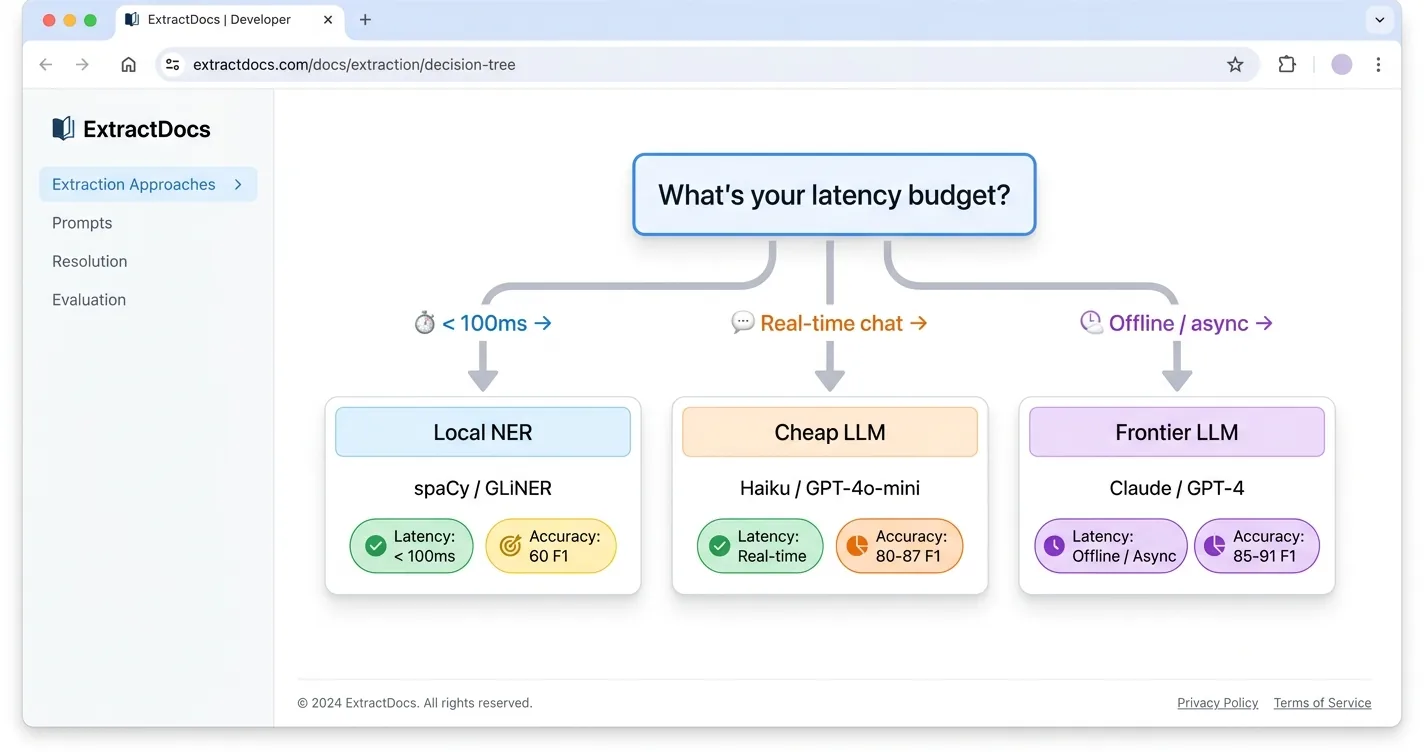
The first real decision in an extraction pipeline is picking the engine that identifies product mentions inside a chatbot reply. You have three credible choices, and they trade off accuracy, latency, and operational complexity in very different ways.
Classical NER is the speed leader but loses a lot of accuracy on product names. spaCy’s en_core_web_trf runs in 5 to 15 milliseconds on CPU but posts only 0.605 F1 on the PRODUCT label per the project’s own benchmarks. GLiNER lands at 20 to 50 milliseconds on CPU with a 60.9 average zero-shot F1 across domains.
A fine-tuned BERT, like Home Depot’s TripleLearn system, can reach 0.93 F1 for its own catalog but needs training data you probably do not have.
| Approach | Typical Latency | Accuracy (F1) | Best For |
|---|---|---|---|
| spaCy transformer NER | 5-15ms CPU | 0.60 | Hard sub-100ms budgets |
| GLiNER zero-shot | 20-50ms CPU | 0.61 | CPU-only, no training data |
| Fine-tuned BERT | 10-30ms GPU | 0.85-0.93 | Single-domain catalogs |
| Cheap LLM (Haiku, GPT-4o-mini) | 300-800ms | 0.80-0.87 | Real-time chat extraction |
| Frontier LLM (Claude, GPT-4) | 800-3,000ms | 0.85-0.91 | Offline enrichment, high precision |
LLM extraction trades speed for accuracy. GPT-4 posts 85 to 91 percent F1 on e-commerce attribute benchmarks such as ExtractGPT and WDC-PAVE, at a cost of 800 to 3,000 milliseconds per call, with Claude typically in the same range. Cheaper models like Haiku or GPT-4o-mini bring latency down to 300 to 800 milliseconds with a modest accuracy hit.
The practical decision rubric comes down to three latency regimes you can slot your use case into. If your total budget is under 100 milliseconds, you need local NER or GLiNER. If the work happens offline or asynchronously, an LLM is usually the right call. For a live chat reply that already took two to five seconds to generate, adding an LLM extraction call is marginal latency for a large accuracy gain, which is why LLM-first is the dominant pattern in 2026.
How Do You Prompt an LLM with a Strict JSON Schema?
A good extraction prompt does two things at once, and getting both right keeps the rest of your pipeline honest. It defines the output shape so you never have to parse free-form text, and it gives the model a few canonical examples of how to populate that shape from messy conversational input.
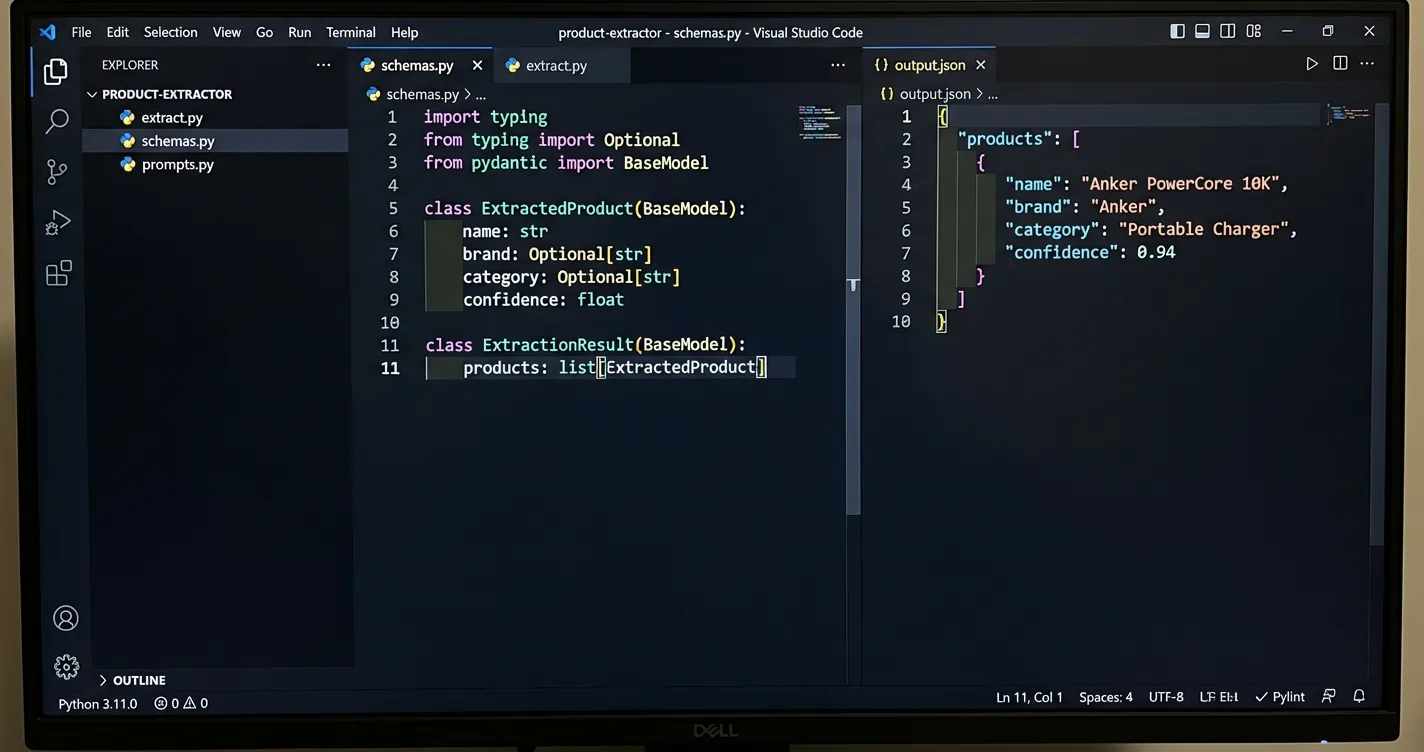
Your baseline schema only needs to cover four fields that downstream resolution actually depends on. You want the product name, an optional brand, an optional category, and a confidence score, which gives you enough signal for filtering and resolution. A minimum Pydantic or JSON Schema definition is enough to drive Anthropic’s strict tool use, OpenAI’s Structured Outputs with the strict flag.
Gemini’s structured output mode works the same way. All three use constrained decoding under the hood, which guarantees schema adherence at the token level instead of hoping the model returns valid JSON on its own.
from pydantic import BaseModel
from typing import Optional
class ExtractedProduct(BaseModel):
name: str
brand: Optional[str]
category: Optional[str]
confidence: float
class ExtractionResult(BaseModel):
products: list[ExtractedProduct]
The prompt should include two or three few-shot examples that mirror real chatbot output, including vague references like “the Anker one” and multi-product sentences. Keep temperature at zero for extraction calls, and include an empty-array example so the model knows an empty reply is allowed. Production reports commonly cite a 5 to 20 percent malformed-output rate for prompt-only approaches without constrained decoding, which is why the strict-schema path is worth the setup cost.
One caveat Google flags in its structured output docs deserves attention. Schema validity is not the same as semantic correctness, and Google’s own best-practices note says it plainly: “while output is syntactically correct JSON, always validate values in your application.” A well-formed JSON response can still contain a hallucinated product, a wrong brand, or a confidence score the model made up. Constrained decoding handles the shape, and a second-pass verifier or confidence threshold handles the truth.
What Chatbot-Specific Failure Modes Need Handling?
Extraction quality on chatbot output is lower than on product pages for reasons that do not show up in standard NER benchmarks. Dialogue research calls it “low information density and high personal pronoun frequency,” so the signal-to-noise ratio for entities is inherently worse than on catalog text.
Three failure modes show up often enough to design around — and any one of them is enough reason that LLMs alone don’t work for AI chatbot monetization without a verification layer in front. The first is hallucination on empty input, which the GPT-NER paper documents in detail: “LLMs have a strong inclination to over-confidently label NULL inputs as entities” and invent products when none were mentioned.
The second is implicit references like “the Anker one” or “that charger,” which depend on coreference resolution that degrades sharply on informal dialogue compared to edited text. The third is raw brittleness. GDELT’s entity-extraction experiments showed that a single apostrophe, turning “NATOs” into “NATO’s”, can erase Latvia and China from the extracted set entirely.
The workable mitigation stack is small, cheap, and stacks well:
- Set temperature to zero so extraction outputs are deterministic
- Add an explicit empty-array path in your schema so “no products here” is a first-class answer
- Retry once on schema validation failure, and pipe messy output through a library like
json_repairbefore giving up - Add a cheap second-pass verifier such as Haiku or GPT-4o-mini, asked whether the source text actually mentions the product, to catch confident hallucinations
Keep a sample of 20 to 30 empty or product-free chatbot replies in your regression set. Extraction systems that never see null examples drift into confident hallucination, and you want that drift caught in CI rather than in production.
How Do You Resolve Extracted Mentions to Real Products?
Pulling “PowerCore 10K” out of a chatbot reply is the easy half of the problem you are solving. Turning that string into a specific Amazon ASIN, or any catalog SKU you can actually buy, is where most pipelines quietly break.
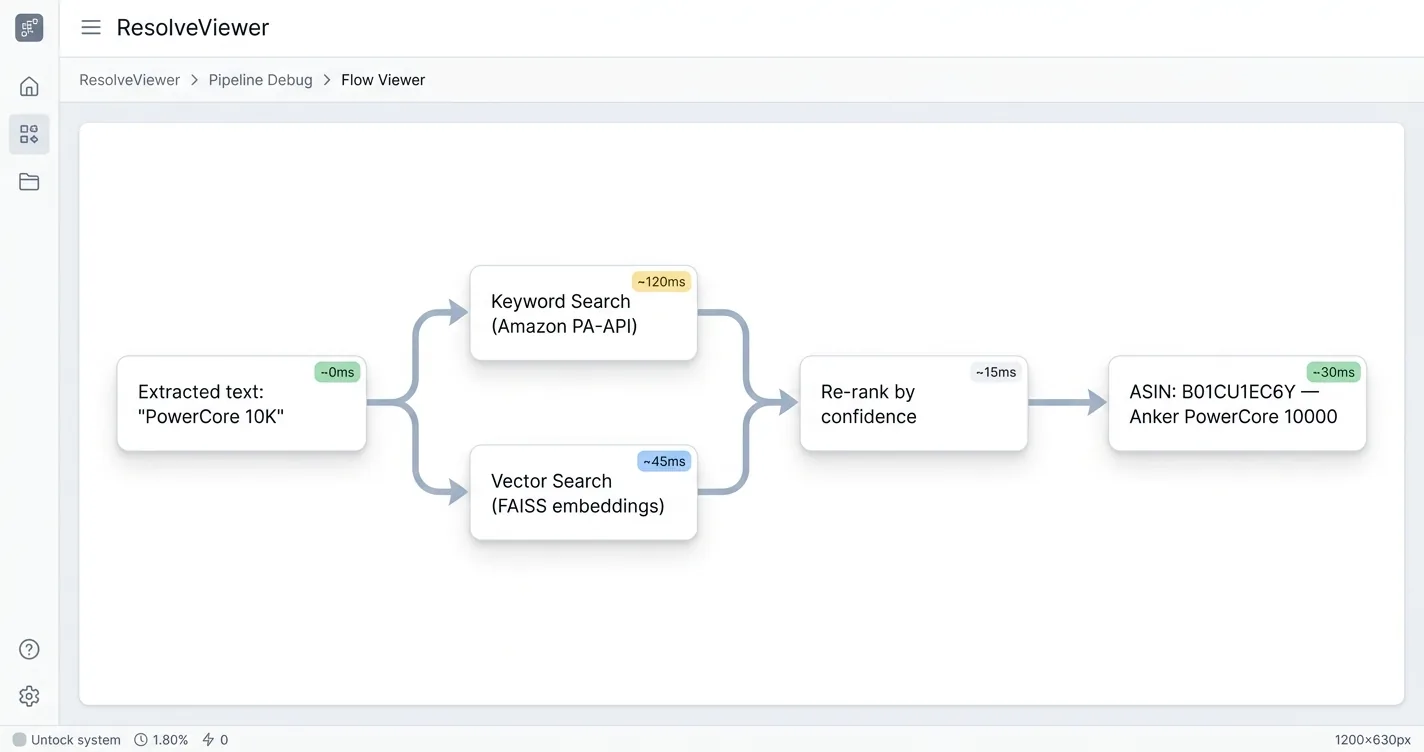
Two strategies dominate the resolution layer, and most working pipelines end up using both. The first is keyword search against a commerce API, most commonly Amazon PA-API 5.0’s SearchItems endpoint. It is easy to adopt and works reasonably for exact brand and product-line matches, but relevance controls are limited, and you end up re-ranking results yourself whenever the extracted mention is fuzzy.
The second is semantic search against an embedded product catalog. Coupang’s engineering team published a detailed write-up on combining text and image embeddings indexed in FAISS for duplicate-catalog matching, reporting that “the recall improved by 106% with the joint true matches” over their old Elasticsearch pipeline. ManoloAI reported similar gains, with transformer embeddings cutting catalog dedup time by 60 percent and raising F1 by 20 percent over TF-IDF baselines. TF-IDF fails cleanly here because it cannot tell that “Large Polo Tee Blue for Men” and “Men’s Blue Polo Shirt Size L” describe the same SKU.
Embed your catalog with a multilingual sentence model, index in FAISS or a managed vector database, and fall back to PA-API keyword search when embedding similarity drops below your confidence floor. The hybrid path handles both exact brand matches and paraphrased mentions without forcing either path to carry the whole load.
OpenAI’s Agentic Commerce Protocol takes a different route by ingesting merchant product feeds that ChatGPT’s shopping retrieval then ranks against, so resolution happens inside the assistant rather than in your code. For developers without feed partnerships in place, a hybrid embedding-plus-keyword approach remains the right trade-off in 2026, and it is what most serious AI chatbot monetization pipelines end up shipping.
Which Library Fits Your Stack?
The library you pick should match how much of the stack you actually want to own. All of these are production-grade in 2026, and the right answer depends on whether you are calling a hosted LLM, serving your own, or trying to avoid the LLM path entirely.
| Library | Best For | Overhead |
|---|---|---|
| Instructor | Python teams using any hosted LLM | Under 10ms on top of the LLM call |
| Outlines | Self-hosted vLLM or SGLang serving | Microsecond FSM decoding |
| BAML | Parsing JSON wrapped in markdown or chain-of-thought | Millisecond Schema-Aligned Parsing |
| GLiNER | CPU-only, sub-50ms inference without an LLM call | 20-50ms zero-shot NER |
Instructor is the default pick for most Python teams running extraction against a hosted LLM. It wraps OpenAI, Anthropic, Gemini, and most open-source providers behind a Pydantic-first interface, describing itself as a way to “extract structured data from any LLM with type safety, validation, and automatic retries,” and it backs that up with over three million monthly downloads as a sanity check on maturity. The overhead is under ten milliseconds on top of the LLM call itself, which is effectively noise in the total latency budget.
Outlines is the better choice when you serve your own models through vLLM or SGLang. Its FSM-based constrained decoding guarantees schema adherence at the token level with microsecond-scale overhead, so you skip the retry loop entirely. BAML solves a narrower but painful problem, namely extracting JSON that the model wrapped in markdown fences or chain-of-thought preamble, and its Schema-Aligned Parsing handles those cases cleanly where strict JSON parsers fail.
GLiNER is the outlier in this list because it skips LLMs altogether. When you need sub-50ms inference on CPU and can accept around 60 F1 on zero-shot product extraction, it is the cleanest drop-in available. For teams that want to skip libraries entirely, Anthropic’s tool-use cookbook documents the zero-dependency pattern using the native SDK.
ChatAds handles the full pipeline (extraction, resolution, and affiliate link injection) behind a single API call. If you want to ship monetization without standing up an extraction service, it is the shortest path, and our roundup of tools for extracting product mentions in AI text compares it against the alternatives. See our write-up on how to add Amazon affiliate ads to your AI app for the integration overview.
How Do You Measure Extraction Quality?
Token-level F1 is a deceptive way to judge an extraction system meant to feed affiliate revenue. What you actually care about is whether the right product entity came out whole, not whether each token inside that entity happened to get tagged correctly.
The canonical framework is the SemEval’13 four-match-type model popularized by David Batista, which scores predictions across Strict, Exact, Partial, and Type matches. Partial matches carry extra weight for product extraction because “Anker PowerCore” and “Anker PowerCore 10000” may or may not resolve to the same ASIN once you hit the catalog. Your metric should reflect that resolution-layer reality instead of flattening it into a single Boolean correctness score.
| Match Type | What Counts |
|---|---|
| Strict | Exact span boundary and correct entity type |
| Exact | Exact span boundary, entity type may differ |
| Partial | Predicted span overlaps the gold span, type correct |
| Type | Correct entity type, boundary may differ |
A minimum evaluation harness is cheaper to build than most teams expect. Hand-label 100 to 200 representative chatbot responses, score them with seqeval or Microsoft’s custom NER evaluation framework, and split labels by product category, because accuracy for any single entity type stabilizes only after around 15 labeled examples per Microsoft’s own guidance.
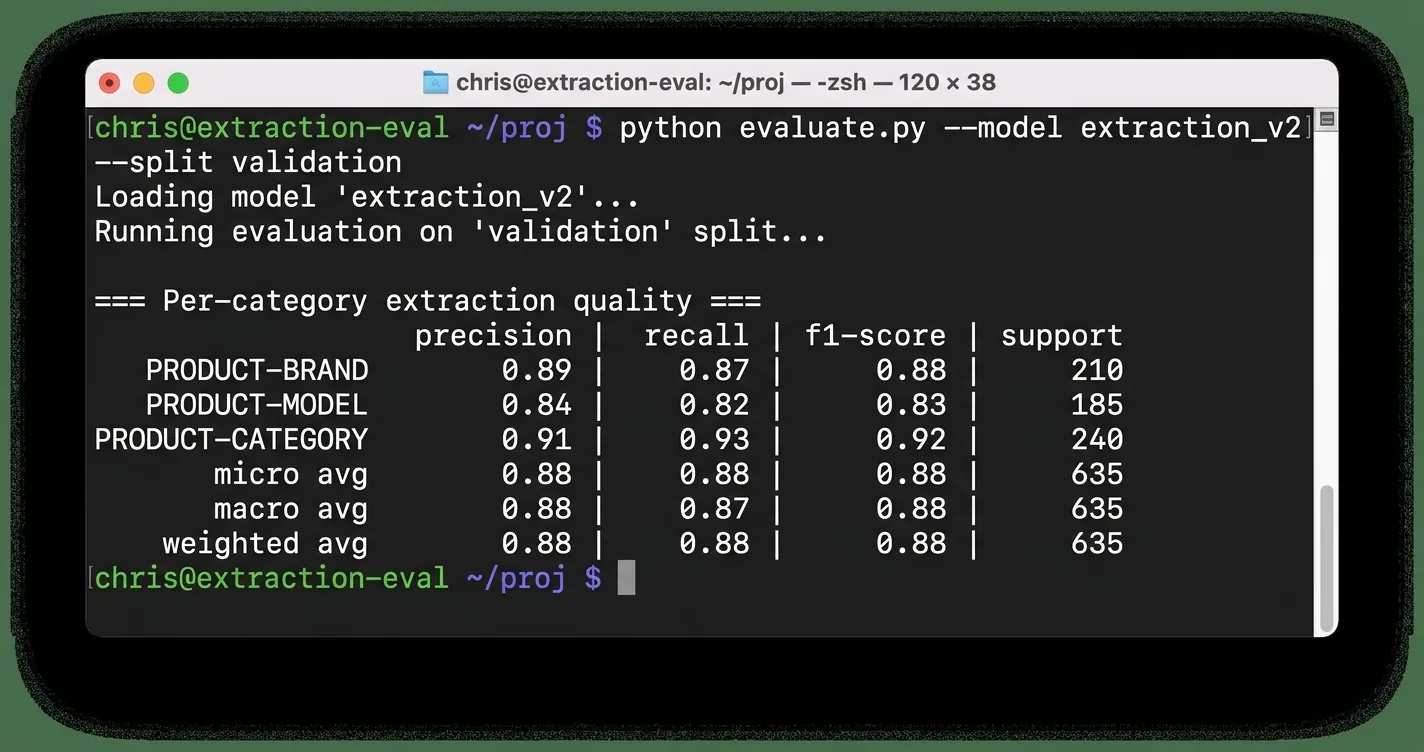
For affiliate use specifically, the precision-recall tradeoff skews hard toward precision. A false positive means your chatbot just linked the wrong product, which hurts trust and can trip FTC guidance on accurate affiliate disclosures. A false negative means you missed a link, which costs revenue but nothing more. Tune thresholds and confidence floors accordingly, and measure both sides of the curve before shipping anything.
Product extraction from AI chatbot output sits at the intersection of four separate problems, and getting any one of them wrong breaks the whole pipeline. Pick the engine that matches your latency budget, wrap it in a schema-strict LLM call when accuracy matters more than milliseconds, handle the chatbot-specific failure modes before they handle you, and resolve extracted strings to real SKUs through a mix of keyword and embedding search.
Measurement is the piece most teams skip, and it is also the piece that keeps precision ahead of recall, which is exactly what affiliate revenue needs. The frameworks, libraries, and benchmarks available in 2026 are mature enough that none of this requires invention, only discipline. If you want to skip the build and go straight to monetization, ChatAds runs extraction, resolution, and link injection behind one API call so your assistant can stay focused on answering users.
Frequently Asked Questions
What's the best way to extract product mentions from AI chatbot responses?
For most real-time chat workloads in 2026, the default is an LLM extraction call with a strict JSON schema, powered by constrained decoding. It lands at 85 to 91 percent F1 on e-commerce benchmarks and adds only marginal latency on top of an AI response that already took seconds to generate. When you need sub-100ms total latency, a local NER model like GLiNER or a fine-tuned BERT is the better fit, at the cost of lower accuracy on messy conversational phrasing.
Is spaCy or classical NER accurate enough for product extraction?
Not on its own for most chatbot use cases. spaCy's best transformer pipeline scores about 0.605 F1 on the PRODUCT label, and popular BERT-based NER models like dslim/bert-base-NER have no PRODUCT class at all. Classical NER is useful as a fast first pass or fallback, but it typically needs fine-tuning on your own labeled catalog data, or pairing with an LLM verifier, to reach the accuracy affiliate use cases demand.
How do I handle implicit product references like "the Anker one"?
Implicit references require coreference resolution, which degrades sharply on informal chatbot dialogue compared to edited text. The most reliable approach is to pass the full conversation history into the LLM extraction call, not just the final response, so the model can resolve pronouns and partial references against earlier product mentions. A cheap verifier pass that checks each extracted product against the source text helps catch resolution errors before they reach your affiliate pipeline.
How do I stop an LLM from hallucinating products that were not mentioned?
Four techniques stack well together. Set temperature to zero for deterministic outputs. Include explicit empty-array examples in your few-shot prompt so "no products" is a first-class answer. Use a strict JSON schema via Anthropic tool use, OpenAI Structured Outputs, or Gemini's JSON mode so constrained decoding enforces shape. Finally, run a cheap verifier pass (Haiku or GPT-4o-mini is enough) asking whether the source text actually mentions each extracted product before linking anything.
Which library should I use for structured LLM extraction?
Instructor is the default for Python teams running extraction against any hosted LLM, with Pydantic-first interfaces and automatic retries. Outlines is better when you serve your own models through vLLM or SGLang, thanks to FSM-based constrained decoding. BAML is the right pick when the model keeps wrapping output in markdown or chain-of-thought, because its Schema-Aligned Parsing recovers JSON that strict parsers reject. Anthropic's tool-use cookbook covers the zero-dependency pattern when you want to avoid libraries altogether.
How do I match extracted product names to real SKUs or ASINs?
A hybrid of keyword search and vector search tends to win. Amazon PA-API 5.0's SearchItems endpoint is fine for exact brand and product-line matches and gives you a baseline quickly. For paraphrased or fuzzy mentions, embed your catalog with a sentence transformer, index it in FAISS or a managed vector database, and match extracted text by cosine similarity. Coupang reported a 106 percent recall improvement over Elasticsearch with this pattern, and ManoloAI reported 20 percent higher F1 than TF-IDF on catalog deduplication.
How should I measure product extraction quality for affiliate use?
Use entity-level metrics, not token-level F1. The SemEval'13 framework scores predictions across Strict, Exact, Partial, and Type matches, and partial matches matter because "Anker PowerCore" and "Anker PowerCore 10000" may resolve to the same ASIN. Hand-label 100 to 200 representative chatbot responses, score them with seqeval or Microsoft's custom NER evaluation framework, and weight precision above recall since false positives link the wrong product and hurt trust more than missed links cost in revenue.